Publications
- Interpolating between Clustering and Dimensionality Reduction with Gromov-Wasserstein, Van Hassel H., Vincent-Cuaz, C., Vayer T., Flamary R., Courty N.
Workshop Optimal Transport and Machine Learning, Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 2023, Workshop)
Links : Paper, Bibtex.
Abstract
We present a versatile adaptation of existing dimensionality reduction (DR) objectives, enabling the simultaneous reduction of both sample and feature sizes. Correspondances between input and embedding samples are computed through a semi-relaxed Gromov-Wasserstein optimal transport (OT) problem. When the embedding sample size matches that of the input, our model recovers classical popular DR models. When the embedding’s dimensionality is unconstrained, we show that the OT plan delivers a competitive hard clustering. We emphasize the importance of intermediate stages that blend DR and clustering for summarizing real data and apply our method to visualize datasets of images. - Template based Graph Neural Network with Optimal Transport Distances, Vincent-Cuaz, C., Flamary, R., Corneli, M., Vayer, T., & Courty, N.
Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022, Oral Paper)
Links: Paper, Bibtex, Slides.
Abstract
Current Graph Neural Networks (GNN) architectures generally rely on two important components: node features embedding through message passing, and aggregation with a specialized form of pooling. The structural (or topological) information is implicitly taken into account in these two steps. We propose in this work a novel point of view, which places distances to some learnable graph templates at the core of the graph representation. This distance embedding is constructed thanks to an optimal transport distance: the Fused Gromov-Wasserstein (FGW) distance, which encodes simultaneously feature and structure dissimilarities by solving a soft graph-matching problem. We postulate that the vector of FGW distances to a set of template graphs has a strong discriminative power, which is then fed to a non-linear classifier for final predictions. Distance embedding can be seen as a new layer, and can leverage on existing message passing techniques to promote sensible feature representations. Interestingly enough, in our work the optimal set of template graphs is also learnt in an end-to-end fashion by differentiating through this layer. After describing the corresponding learning procedure, we empirically validate our claim on several synthetic and real life graph classification datasets, where our method is competitive or surpasses kernel and GNN state-of-the-art approaches. We complete our experiments by an ablation study and a sensitivity analysis to parameters.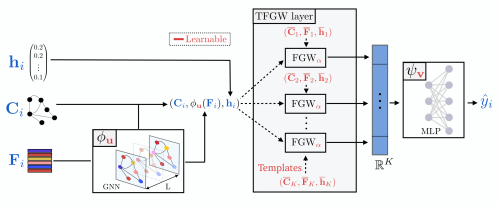
- Semi-relaxed Gromov-Wasserstein divergence with applications on graphs, Vincent-Cuaz, C., Flamary, R., Corneli, M., Vayer, T., & Courty, N.
International Conference on Learning Representations (ICLR 2022).
Links: Paper, Bibtex, Github repository.
Abstract
Comparing structured objects such as graphs is a fundamental operation involved in many learning tasks. To this end, the Gromov-Wasserstein (GW) distance, based on Optimal Transport (OT), has proven to be successful in handling the specific nature of the associated objects. More specifically, through the nodes connectivity relations, GW operates on graphs, seen as probability measures over specific spaces. At the core of OT is the idea of conservation of mass, which imposes a coupling between all the nodes from the two considered graphs. We argue in this paper that this property can be detrimental for tasks such as graph dictionary or partition learning, and we relax it by proposing a new semi-relaxed Gromov-Wasserstein divergence. Aside from immediate computational benefits, we discuss its properties, and show that it can lead to an efficient graph dictionary learning algorithm. We empirically demonstrate its relevance for complex tasks on graphs such as partitioning, clustering and completion.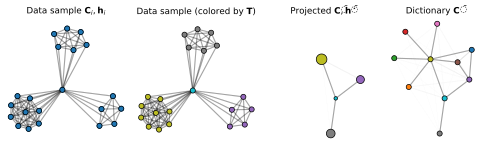
-
Semi-relaxed Gromov-Wasserstein divergence for graphs classification, Vincent-Cuaz, C., Flamary, R., Corneli, M., Vayer, T., & Courty, N. XXVIIIème Colloque Francophone de Traitement du Signal et des Images (Colloque GRETSI 2022). Links: Paper, Bibtex, Github repository.
- Online Graph Dictionary Learning, Vincent-Cuaz, C., Vayer, T., Flamary, R., Corneli, M. & Courty, N.
International Conference on Machine Learning (ICML 2022, Spotlight Paper).
Links: Paper, Bibtex, Video, Github repository, POT implementation.
Abstract
Dictionary learning is a key tool for representation learning, that explains the data as linear combination of few basic elements. Yet, this analysis is not amenable in the context of graph learning, as graphs usually belong to different metric spaces. We fill this gap by proposing a new online Graph Dictionary Learning approach, which uses the Gromov Wasserstein divergence for the data fitting term. In our work, graphs are encoded through their nodes’ pairwise relations and modeled as convex combination of graph atoms, i.e. dictionary elements, estimated thanks to an online stochastic algorithm, which operates on a dataset of unregistered graphs with potentially different number of nodes. Our approach naturally extends to labeled graphs, and is completed by a novel upper bound that can be used as a fast approximation of Gromov Wasserstein in the embedding space. We provide numerical evidences showing the interest of our approach for unsupervised embedding of graph datasets and for online graph subspace estimation and tracking.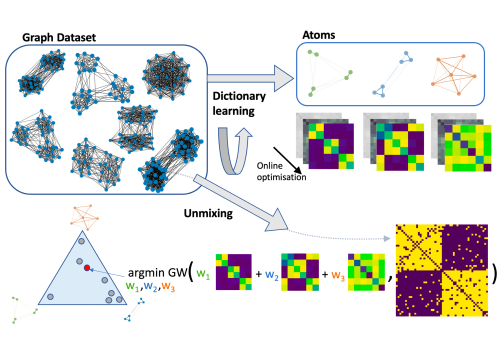
Thesis
- Optimal Transport for Graph Representation Learning, Vincent-Cuaz, C. Supervisors: Rémi Flamary, Marco Corneli. Jury President: Marco Gori Jury reporters: Florence D’Alché-Buc, Gabriel Peyré. Jury reviewers: Laetitie Chapel, Hongteng Xu.
Links: Manuscript, slides.
Preprints
None for now.
Python Optimal Transport Library
Some content for the wonderful POT library that I help to main.
- Details on the Conditional Gradient solvers for the Gromov-Wasserstein distance: An unfinished note